Recently, Thoughtworks released a new version of their Technology Radar. The Technology Radar is a list of technologies that the editors at Thoughtworks consider important and valuable to try. I read each edition of their Technology Radars because they usually provide a list of new approaches and services, and it helps me validate whether my understanding of the current state of IT is still valid or if I have missed something new and important.
30th Volume
The last two releases of the Technology Radar have focused heavily on ML/AI/LLM technologies, and this release features the maximum number of technologies. It seems they are betting on these technologies and expect continued growth.
Another interesting part is that the Technology Radar includes at least 80% new technologies. There’s an unusual amount of new tooling that they have started to use in their products, and I have questions about how it relates to their legacy code and what they do with other solutions.
However, this release is interesting, and I will split my review into a few categories: ML, Infrastructure, Frontend/Mobile.
ML/AI/LLM
The list includes a pack of technologies related to the RAG system and many tools for improving DevX.
RAG
RAG (Retrieval Augmented Generation) was introduced about 1.5 years ago. The main idea is to provide actual data for ML models. ML models are just binaries that are trained once and reused for a long time. Retraining is a very expensive operation that requires millions of dollars. Now, the common approach is using Fine Tuning (for fast, small re-training) and RAG, which provides actual context based on text for LLMs.
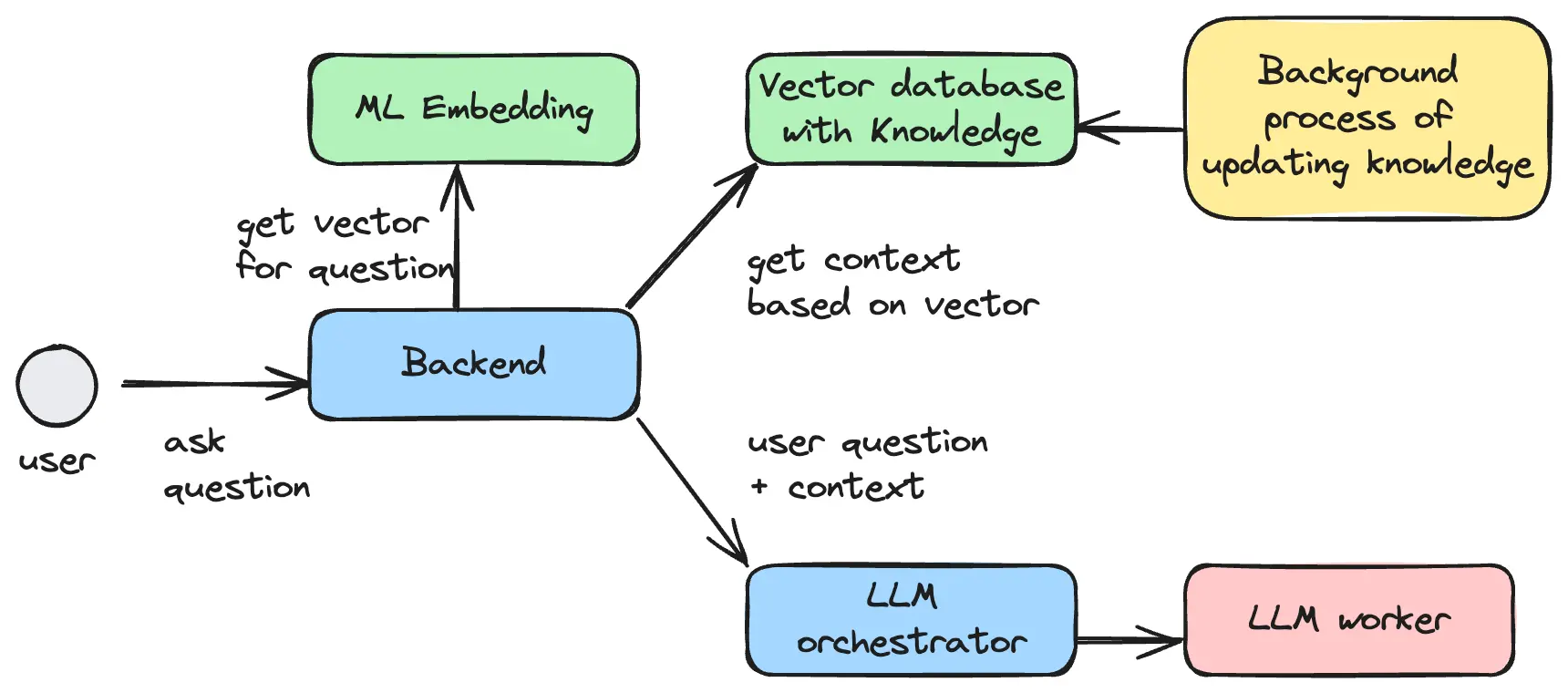
-
Vector databases are a new type of database that can store vectors from ML embeddings and search for similar information. They work like ElasticSearch but understand the context of a query and related information much better. As an implementation of this layer, they use qdrant, an open-source, self-hosted solution with good clients, or a new ElasticSearch AI extension: https://www.elastic.co/elasticsearch/elasticsearch-relevance-engine for vector search data.
-
LLMs are models that can generate answers based on queries, like ChatGPT. The list includes various technologies such as:
- Mistral is one of the top available open-source models that we can run as a self-hosted solution. However, the main problem is that the models are released very often, and the top models change every 2-6 months. For example, Lama 3 was released and is now better than Mistral.
- Baichuan 2 is an unpopular open-source LLM trained for specific domains like healthcare. Generally, it’s not so useful for common purposes.
- Gemini Nano is a small model from Google for Android phones; personally, I don’t know what the model here is because it’s closed-source, and only one type of phone can run it.
- The OpenAI API has started to become a standard in the LLM world, like S3 for storage. As a result, many tools provide implementations of this API and help set up your own backend, which you can use in any cases that support the OpenAI API. Solutions like vLLM can help do this, plus address more typical problems related to running LLMs on servers.
-
LLM Orchestrator https://github.com/ray-project/ray is an interesting solution that helps organize the process of training/tuning models. It’s like the MapReduce pattern but created for ML.
-
Backend - At the backend level, we still need to have logic that creates prompts for LLMs, fetches data from knowledge bases, and performs other tasks. For this, they recommend using https://github.com/BerriAI/litellm as a simple solution. However, https://www.langchain.com/ is not recommended because it’s too complex and fragile.
For fine-tuning LLMs, they recommend using https://github.com/hiyouga/LLaMA-Factory, which supports many optimizations and different LLM models.
AI Tools
- Coding Assistance - The list includes typical examples like GitHub Copilot and other solutions like aider for terminals, codium.ai for tests, and continue for editors using local LLMs.
- https://github.com/langgenius/dify is another visual builder of workflows. I still don’t know why I need to use it, but maybe it will be a good solution for visualizations of agents.
Infrastructure
A significant part of the Technology Radar is self-hosted infrastructure. It seems they want to avoid cloud provider lock-in and spend resources discovering and using open solutions.
Infrastructure as Code
This is still a hot topic that is actively growing. Solutions like Pulumi have started to mature, and new generations of tools have begun to emerge.
- https://www.pulumi.com is one of the most popular solutions for Infrastructure as Code. Instead of creating infrastructure in the AWS web interface, we can write TypeScript code that will bootstrap what we wrote in the code.
- https://github.com/tenable/terrascan is for scanning Infrastructure as Code. This is a big topic because cloud providers make it easy to do insecure things like opening your database to the internet or making internal Lambdas accessible to everyone. This solution can help prevent these issues and find problems in your specifications.
- https://www.winglang.io/ is an alternative to Pulumi but has its own language, UI interface for visualization, and an abstraction over cloud providers and configurations. In Pulumi, we need to provide all configurations for cloud providers, similar to calling an API. Because APIs differ, we cannot use our configuration from AWS for Google Cloud. Winglang solves this by creating an abstraction over typical use cases for applications. It looks good and solves one of the problems of Infrastructure as Code with complex and non-reusable configurations.
- https://www.systeminit.com/ - The main idea is Infrastructure as Code plus visualization plus collaboration. It’s an interesting concept that helps better understand how a project really works and the connections between parts. It might help because if you have a big project, it’s sometimes not easy to understand the high-level structure of the project.
Observability
- https://github.com/hyperdxio/hyperdx - Generally, we have three separate concepts: logs, traces, and metrics. Very often, all of them are stored in different systems like Grafana, Kibana, and Jaeger. But if we need to debug a problem, we often need to see all of them together. This approach implements it for two types of sources: logs and traces, making them available in one place.
Kubernetes
There aren’t many technologies for Kubernetes. It appears that the Kubernetes ecosystem has stabilized and is not growing much.
- https://karpenter.sh/ - A self-hosted approach for autoscaling Kubernetes nodes/pods applications.
- https://velero.io/ - Just a backup system for Kubernetes that supports different types of Kubernetes installations.
Frontend
The list doesn’t have significant changes and only includes a few options related to Frontend/Mobile. I will discuss them broadly:
-
https://pinia.vuejs.org/ - Pinia is a state manager for VueJS, which is the recommended approach for VueJS. By implementation, it is close to the Mobx state manager from the React world.
-
https://astro.build/ - Astro is a framework for generating sites from content and supports an interesting “islands” approach, which allows the use of any frontend frameworks like React, VueJS, Angular. The core of Astro is a compiler that receives content and generates HTML files, but the core is very small and allows engineers to use whatever they want. Astro is one of the best approaches for generating static websites at the moment. This site is also based on Astro.
-
https://voyager.adriel.cafe/ - A routing solution for mobile applications, utilizing an interesting approach related to nested routes/pages, where we can open one page, inside which we can have second pages and so on.
-
https://github.com/electric-sql/electric - One of the most challenging parts of complex applications is managing state. Usually, most web applications only work if you have an internet connection. Only a few applications are offline first. But if an engineer wants to create offline-first applications, it creates a lot of complexity. Electric tries to solve part of this complexity by managing local storage for clients, which will automatically sync with the backend when the internet is available. I agree that such technologies are very important, but I have seen many similar technologies over the last 6 years, and it still is not a common approach.
Developing Tools
- https://pkl-lang.org/ - Good tooling if you have large configuration files that will be used by other engineers. Complex configurations are easy to mishandle, requiring parsing of different formats, setting default values, etc. Previously, I solved similar issues just based on TypeScript types, which I transformed into a JSON schema that I use to validate user configurations. However, it looks like a complete solution that I would try to use as a replacement.
- https://github.com/maypok86/otter - An LRU-like cache with good performance. Based on an approach that I describe in my article related to cache.
- https://github.com/chanhx/crabviz - A plugin for VSCode that uses language servers to generate connections between files. This functionality is usually available in IDEs like JetBrains IDEA, but here it is open-source, supports multiple languages, and looks better than the alternatives.
- https://github.com/datahub-project/datahub - Storing data. Datahub developers have a good explanation of why it is needed at https://www.linkedin.com/blog/engineering/data-management/datahub-popular-metadata-architectures-explained.
My Predictions Related to Next Radars
ML will continue to grow
I think at least in three aspects, ML will improve in the future:
- Quality of models. Every six months, the quality of models improves, which opens access to new types of tasks. But this is obvious.
- Good small models. Currently, LLM models require a lot of GPU memory or are slow, which limits cases of local usage. 8b models we can run locally on ordinary hardware but still have concerns about quality and speed. I think in the future, we will see more 2b models which provide reasonable quality and performance, opening access for a lot of local software that would use LLM in mobile phones, open-source projects, and games.
- Agents. Currently, a lot of our usage is models that answer one question at a time. However, many papers show that this isn’t the optimal solution because models can generate sometimes strange answers. A better approach is to generate five answers and use a different LLM query to choose the best/common answer. Also, we can set up different personalities, which would increase the performance of operations. Additionally, we can add knowledge from databases and the internet. We can do it manually, but it isn’t optimal. As a solution, we could use an Agent approach where we set up a system that asks LLM multiple times, reviews answers, searches for information, searches for additional information, and many other things. Systems that implement basic ideas exist now, but there still isn’t a common solution for the majority of users, and the quality of LLM models doesn’t allow for it. However, this is a big topic that I think will significantly improve with new releases of LLM and finding new approaches.
Improvements in Observability
More tools will arrive that collect all types of data from our services and aggregate them in one interface. Currently, we usually have logs, metrics, and traces that we need to analyze in different interfaces. But we can combine all this data at the source and show it in one interface based on tracings. This significantly helps to find problems in services.
Also, we will see new tools that use LLM for analyzing metrics/alerts. LLMs will have the option to create early alerts that a system might have problems, also LLM can help with choosing critical levels of problems and find similar problems in the past.