Как работает сеть? За 10 лет работы инженером у меня возникло множество вопросов о сети, некоторые из которых я либо не понимал, либо интерпретировал неверно. Такое происходит потому, что сеть эффективно абстрагирует всю эту сложность от нас и значительно упрощает жизнь. Однако иногда отсутствующие знания сказывались на мне; например, на собеседовании меня спросили: “Какой именно нужен балансер в этом месте: OSI L3 или OSI L4?”, и я не мог точно ответить. Или, как пакет передаётся по сети и как это связано с TCP/UDP? Что такое подключение? Как устроены дата-центры изнутри и как они подключены к интернету? Как работают BGP и anycast и куда они анонсируют информацию о себе? Недавно я решил закрыть эти пробелы и начал изучать устройство сети, что и стало основой для этой статьи. Статья будет полезна разработчикам и SRE-инженерам, поскольку наши системы становятся больше, разворачиваются в нескольких дата-центрах, а значит нам нужно лучше понимать сеть, для более качественного результата. Я постараюсь добавить детали, которые были бы интересны мне как разработчику. Если вы — network engineer, то, возможно, многое из этого вы уже знаете, так что оставляйте ваши комментарии и корректировки.
Начинаем с простого
Как работает сеть? Можно начать с простого:
- User — пользователь, который хочет получить данные с backend.
- Backend — это наше приложение, которое отдаёт HTML-страницы.
Но разве всё так просто в реальности?
DNS - как определить, куда подключаться?

DNS (Domain Name System) — это система, которая позволяет нам находить IP-адреса по доменным именам. Это своего рода картотека: мы приходим с доменом example.com и получаем список IP-адресов для подключения. Перед запросом на сервер, браузер и другие системы сначала обращаются к DNS-резолверу и получают IP-адрес, который будет использоваться для подключения, так как весь интернет работает по вверх IP-адресов.
В DNS это выглядит так:
example.com. 300 IN A 203.0.113.1,
example.com. 300 IN A 203.0.114.1,
example.com. 300 IN A 203.0.115.1Здесь список A-записей, которые будут случайно выбираться клиентом при подключении. Если один из IP-адресов не отвечает, клиент переключается на другой. Существуют также AAAA-записи для IPv6.
GEO DNS позволяет привязать DNS записи к регионам. Так, мы можем в разных регионах, например, в Европе и Америке, предоставлять разные IP-адреса, распределяя трафик и направляя пользователей в ближайший дата-центр.
Масштабирование обработки трафика с помощью уровней OSI
Если у нас есть только один бэкенд и мы стремимся обработать значительный объем трафика, добавив еще 20 бэкенд-приложений, как это можно реализовать?
Уровни OSI представляют собой виртуальное разделение сетевой структуры на слои. Это делается для упрощения описания систем и оборудования, а также для разграничения ответственности между слоями. Более нижние уровни не имеют информации о верхних, и каждый последующий уровень добавляет данные к предыдущим. Эту структуру можно представить как стек данных Stack = […Layer 7, …Layer 4, …Layer 3, …Layer 2].
Добавляем OSI Layer 7 — Application Load Balancing
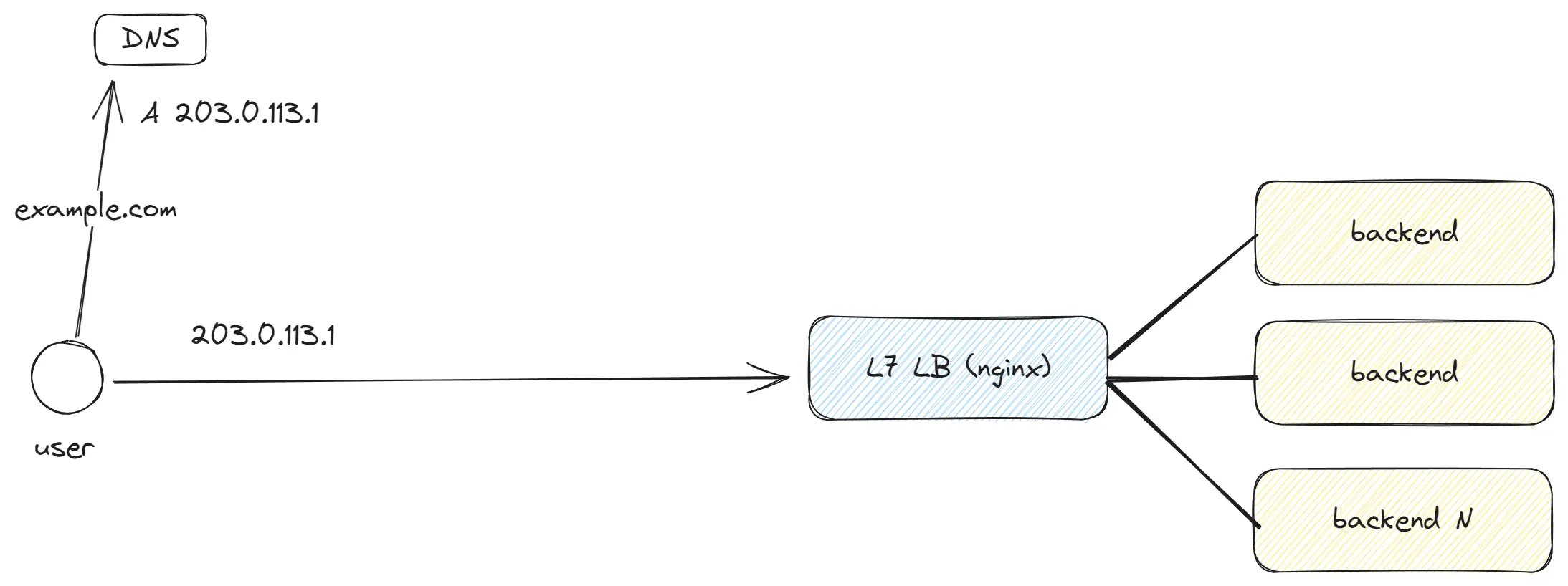
OSI Layer 7 — это самый верхний уровень, где мы работаем с запросами, содержащими полный набор данных.
Стоит помнить следующее:
- Существуют разные application layer protocol: HTTP 1, HTTP 2, HTTP 3, gRPC, WebSockets.
- HTTP 1, HTTP 2 и WebSockets работают поверх TCP, в то время как HTTP 3 использует QUIC.
- Не обязательно использовать L7 LB; можно выбрать L4 LB, который будет проксировать трафик напрямую к вашему бэкенд-приложению. Однако в этом случае бэкенд-приложению придется самостоятельно устанавливать HTTPS-соединения, и не будет остальных L7 LB фич.
- L7 LB позволяет балансировать трафик в зависимости от путей, кук, заголовков, осуществлять сжатие и распаковку данных, кэширование, добавление заголовков, http keepAlive и многое другое.
Пример формата данных на примере текстового формата HTTP 1.0: Request:
GET / HTTP/1.0
Host: example.com
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64)
Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8Response:
HTTP/1.0 200 OK
Content-Type: text/html; charset=UTF-8
Content-Length: 138
Date: Sat, 30 Oct 2021 17:00:00 GMT
<html>
<head>
<title>Example Domain</title>
</head>
</html>Сначала идут заголовки, затем разделитель, а после — тело с данными. Всё это отправляется на Layer 4, где происходит дальнейшая обработка.
Добавляем OSI Layer 4 - Transport Load Balancing
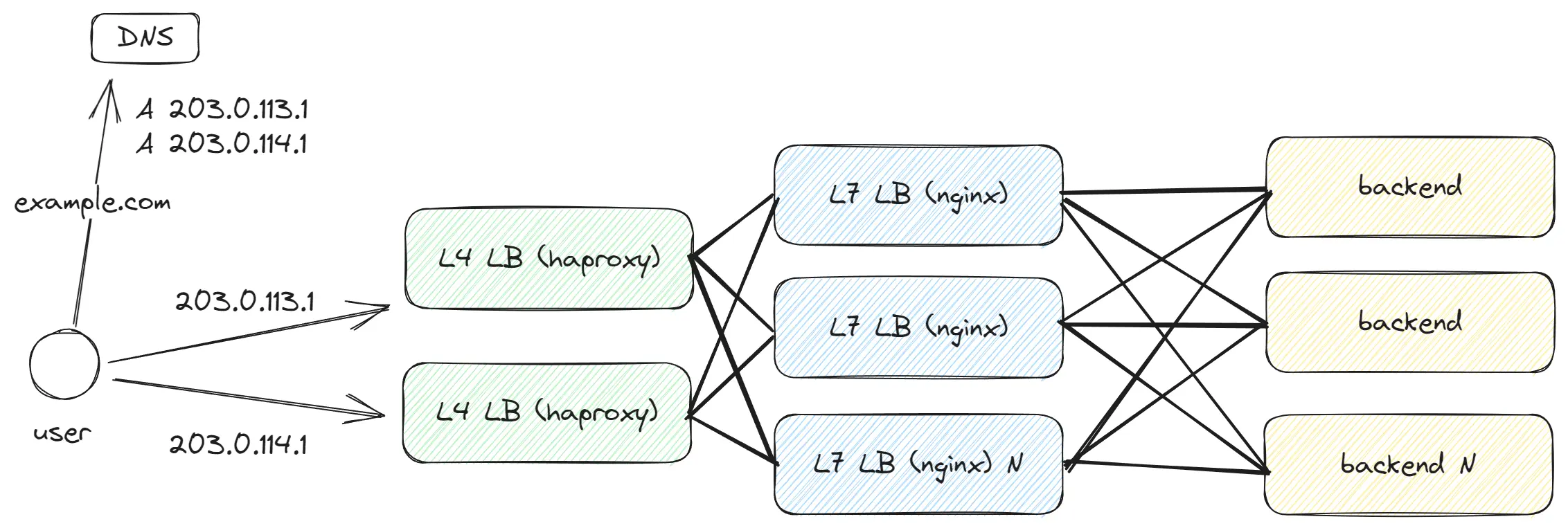
Мы хотим обрабатывать больше трафика и количество LB начинает существенно увеличиваться, это создаёт проблему для DNS — нам приходится прописывать десятки IP-адресов. Есть ли более эффективный способ? В качестве решения мы вводим ещё один уровень абстракции и добавляем L4 LB, который будет балансировать трафик между нашими L7 LB. L4 LB работает быстрее и способен обрабатывать больше трафика, так как он проще устроен по сравнению с L7, и это позволяет нам продолжать масштабирование L7 LB.
Layer 4 — Transport Layer, работает с TCP/UDP, и на этом уровне доступны лишь функции TCP/UDP транспортного протокола. Мы не имеем информации о пути, заголовках запроса и других деталях, знаем только порт и IP-адрес.
TCP
TCP (Transmission Control Protocol) — это протокол, активно используемый в интернете. На его основе построены HTTP 1 и HTTP 2. Внутри TCP запрос разбивается на множество Segment с данными размером до 1460 bytes (20 bytes в заголовках). Пример данных (в реальности это набор байтов, а не JSON):
{
"source_port": 49562,
"destination_port": 443,
"sequence_number": 123456,
"acknowledgment_number": 789012,
"data_offset": 5,
"flags": { SYN: 1, ACK: 0, ... },
"window_size": 65535,
"checksum": "0x1a2b3c4d",
"data": "Encrypted (or plain) payload from higher layers..."
}TCP требует установки соединения между клиентом и сервером. Это достигается через 3 этапа, включая отправку 3 пакетов:
Client -> Server: SYN- клиент инициирует соединение, указывая свой ISN (initial sequence number).Server -> Client: SYN, ACK- сервер отвечает, предоставляя свой ISN и ACK, который равен ISN клиента + 1 (учитывая отправленный клиентом пакет)Client -> Server: ACK- клиент подтверждает готовность к обмену данными
То есть, для установки TCP-соединения требуется 3 пакета, и это может стать проблемой при больших задержках (например, 300 мс) между клиентом и сервером. Но, это требование TCP от которого мы не можем уйти, так как ISN затем используется для определения порядка пакетов. После создания соединения клиент и сервер будут держать активным TCP keepAlive, что позволит им держать соединение открытым в течение длительного времени.
Одна из главных фич TCP — Reliability: он гарантирует доставку данных. Если пакет не доставлен, он будет повторно отправлен. Но, как я указал ранее, один TCP Segment составляет 1460 байт. Если ожидать подтверждения от сервера по доставке каждого сегмента, это потребует огромного количества времени. Для решения этой проблемы в TCP применяется механизм Window Size, который позволяет отправлять пачку Segment и дожидаться подтверждения для всей группы.
По умолчанию Window Size составляет 65535 байт, что позволяет отправлять 45 сегментов до получения подтверждения. Но даже 65535 байт — это не так много. Для ускорения передачи данных в TCP применяются алгоритмы Congestion control, которые позволяют увеличивать размер Window Size в зависимости от качества канала между клиентом и сервером.
Способы оптимизации:
- Стоит включить TCP BBR для более быстрой передачи файлов
- Включите TCP Window Scaling, чтобы увеличить максимальный размер Window Size до 1 ГБ.
- Включите TCP Fast Open - для сокращения количества раундтрипов при установке соединения.
UDP
UDP (User Datagram Protocol) — это простой протокол, который не предоставляет многие функции, доступные в TCP, но зато UDP легковесный. UDP разбивает запрос на Datagrams размером до 1472 байт (8 байт в заголовках). Пример данных (в реальности это набор байтов, а не JSON):
{
"source_port": 49562,
"destination_port": 443,
"length": 1472,
"checksum": "0x1a2b3c4d",
"data": "Encrypted (or plain) payload from higher layers..."
}В отличие от TCP, UDP не гарантирует доставку данных, поэтому если необходима гарантированная доставка, то нужно реализовывать это самостоятельно.
QUIC
QUIC (Quick UDP Internet Connections) — это новый протокол, основанный на UDP и имеющий аналогичный формат Datagram. Для большинства серверов трафик QUIC сложно отличить от UDP. Однако QUIC реализует все ключевые функции, присущие TCP, и в некоторых аспектах даже превосходит его. Основная причина создания QUIC заключается в том, что TCP трудно модифицировать из-за его широкого использования на десятках тысяч серверов, и для улучшения качества доставки контента в TCP необходимы серьезные изменения. Поэтому был разработан QUIC, который строится на основе UDP и добавляет к нему новые функции. QUIC используется в HTTP 3.
What can you read next? https://www.smashingmagazine.com/2021/08/http3-core-concepts-part1/
Добавляем OSI Layer 3 - Network Load Balancing
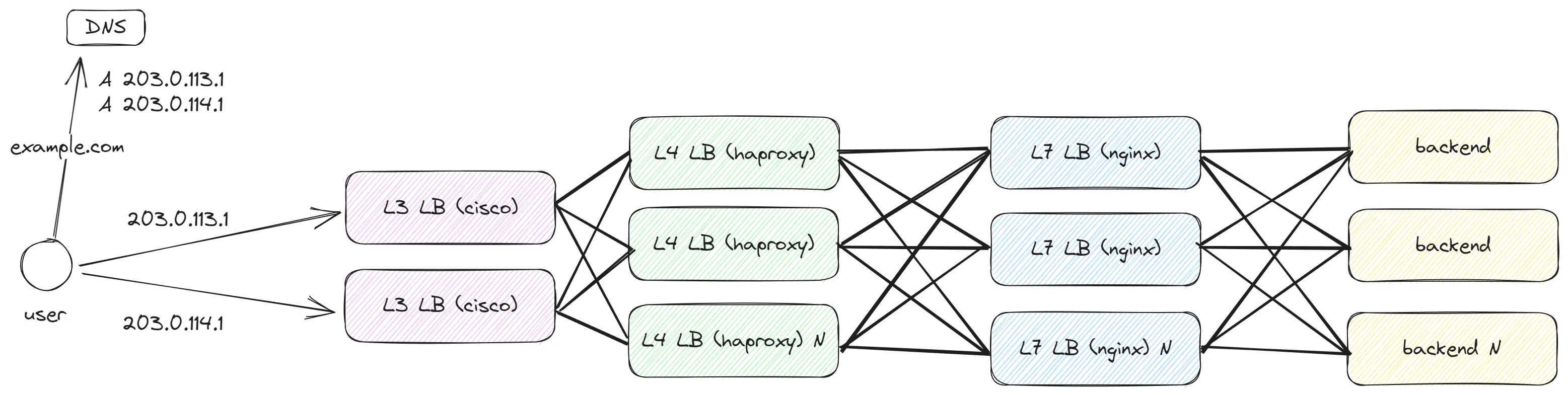
Нам требуется обрабатывать ещё больше трафика и нужна дополнительная абстракция перед L4 для масштабирования количества L4 LB, то решением становится добавление L3 LB, который будет балансировать трафик между нашими L4 LB.
На Layer 3 передаются пакеты Packet, которые уже предаются по сети. На этом уровне доступны только sourceIP и destinationIP. Пакет имеет размер до 1500 байт (20 байт — это заголовки) и следующий формат:
{
"sourceIP": "192.168.1.10",
"destinationIP": "93.184.216.34",
"TTL": 64,
"protocol": "TCP" | "UDP",
"data": "{ Entire L4 segment|datagram... }"
}Основные моменты:
- На этом уровне в общем и целом не важно, используется ли
http2,http3,TCPилиUDP, так как всё это — просто пакеты, передаваемые от сервера к серверу. - Пакеты идут как от клиента к серверу, так и наоборот. Для клиента формируется пакет с
destinationIP, равным “target”, при этом добавляетсяsourceIPклиента. Для сервера пакет формируется сdestinationIP, равнымsourceIPклиента. - Во время передачи пакеты могут идти разными путями. Например, один пакет может идти через
Провайдер A, а другой — черезПровайдер B. В результате пакеты могут приходить в разной последовательности. - Пакеты могут теряться из-за использования разных путей, которые могут быть перегружены. Именно поэтому в
TCPиспользуются алгоритмыCongestion control, позволяющие повторно отправлять потерянные пакеты. - На этом уровне нет понятия
сессии. Пакеты идут, как им вздумается, исессияизTCP— это лишь договоренность между клиентом и сервером, которая не влияет на передачу пакетов в сети.
Способы оптимизации:
- Включить ECMP - это позволит использовать несколько путей для передачи пакетов.
- Включить Anycast - благодаря этому в разных точках мира можно использовать один и тот же IP-адрес, что уменьшит задержку и повысит доступность.
Как сеть устроена между пользователем и сервером?
Современный интернет представляет собой множество кабелей, по которым передаются данные. При этом кабелей ограниченное количество, а типы клиентов разнообразны: от обычного пользователя, желающего посмотреть YouTube, до огромного дата-центра с тысячами серверов. Для связи всех клиентов между собой существуют разные типы сетей, соединённых между собой кабелями и передающих друг другу трафик. Разные уровни платят друг другу за передачу данных, поэтому стремятся оптимизировать трафик на своем уровне. Обычный клиент, подключившийся к интернету, начинает свою работу с Tier 3 и далее использует все остальные уровни.
ISPs and peering
Tier 3 (локальный уровень)
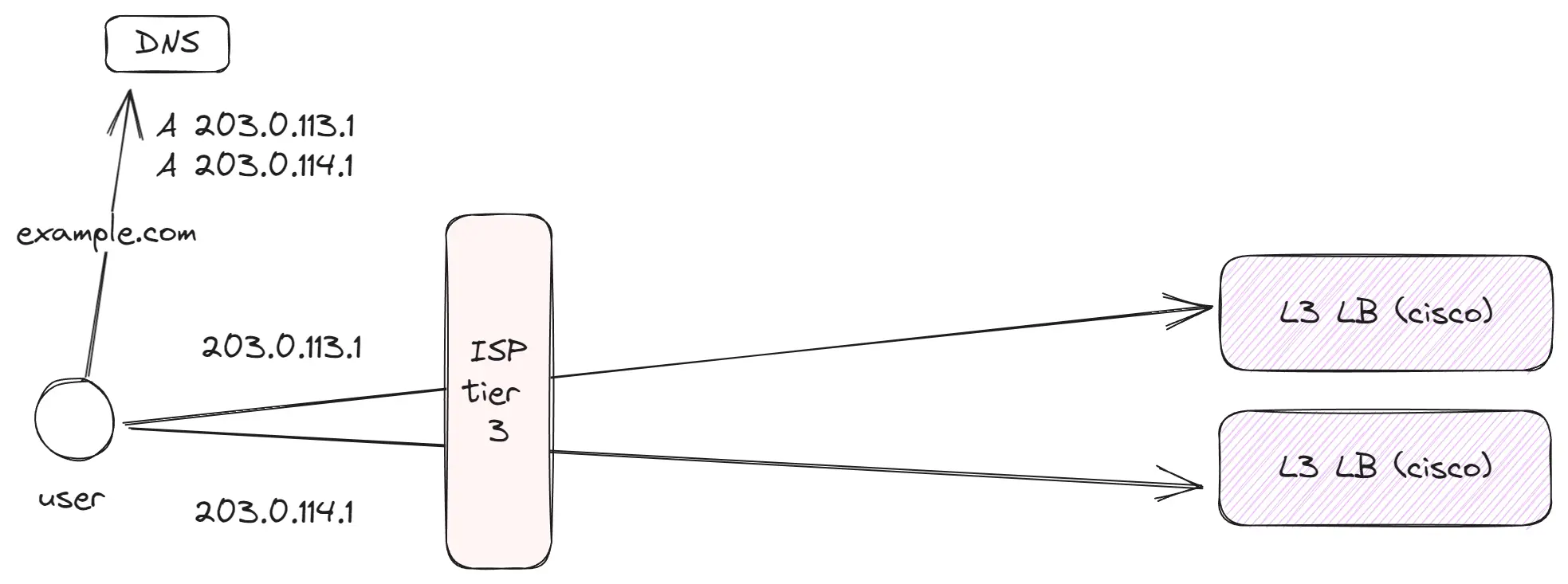
Это тысячи небольших провайдеров в городах и регионах, которые являются первым звеном для обычных клиентов. Затем эти провайдеры покупают или используют выделенные каналы к более крупным провайдерам Tier 2, которые в свою очередь передают трафик в глобальный интернет.
Основные моменты:
- Внутри
Tier 3обычно находятся клиенты одного провайдера или объединение провайдеров, если между ними налажен пиринг. - Обычные пользователи используют
Tier 3для доступа к данным. Например, дома я пользуюсь такой сетью для интернета. - Уже на этом уровне некоторые компании, генерирующие большой трафик (например, YouTube или Netflix), размещают своё кэширующее оборудование. Это помогает снизить нагрузку на сеть провайдеров и улучшить качество обслуживания.
Tier 2 (региональный уровень)
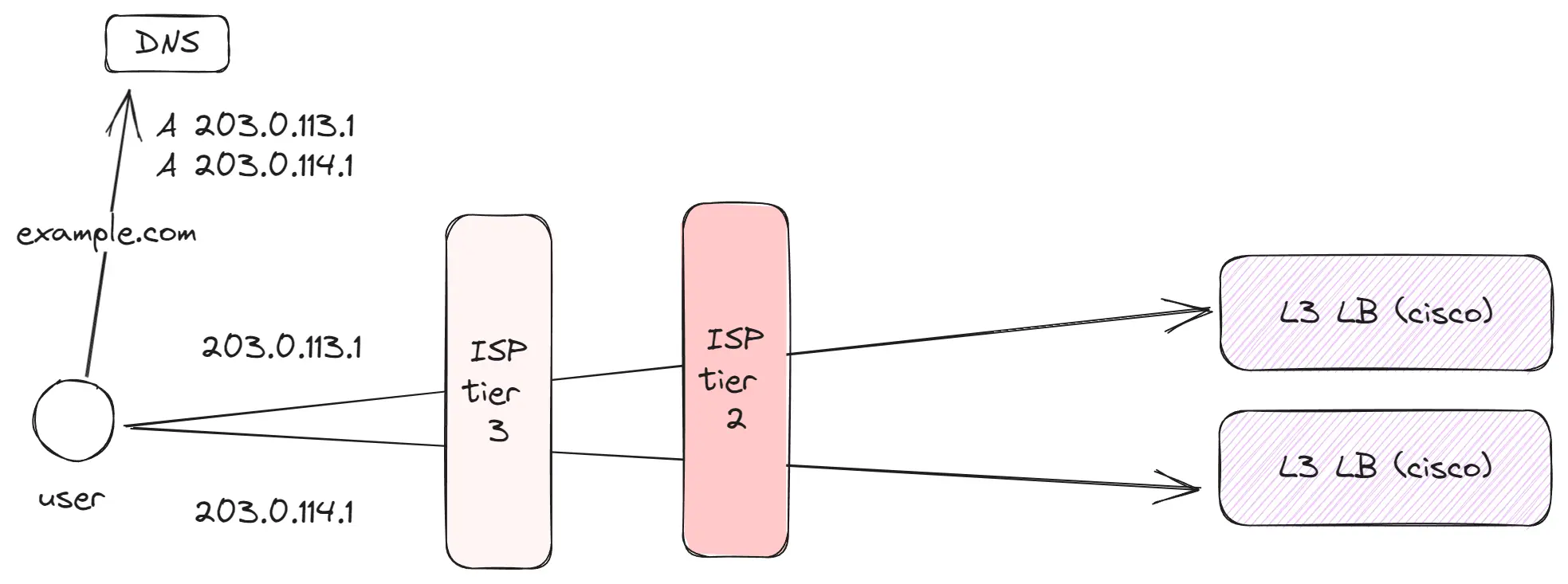
Это сотни крупных или региональных провайдеров, обслуживающих большое количество клиентов. Они ориентированы на более локальный или региональный трафик. Tier 2 соединяются с соседними провайдерами Tier 2 и используют Tier 1 для доступа к глобальному интернету.
Основные моменты:
- На этом уровне располагаются Edge-серверы компаний, таких как Amazon, Google и Facebook, чтобы их оборудование было максимально близко к конечным пользователям.
Tier 1 (глобальный уровень)
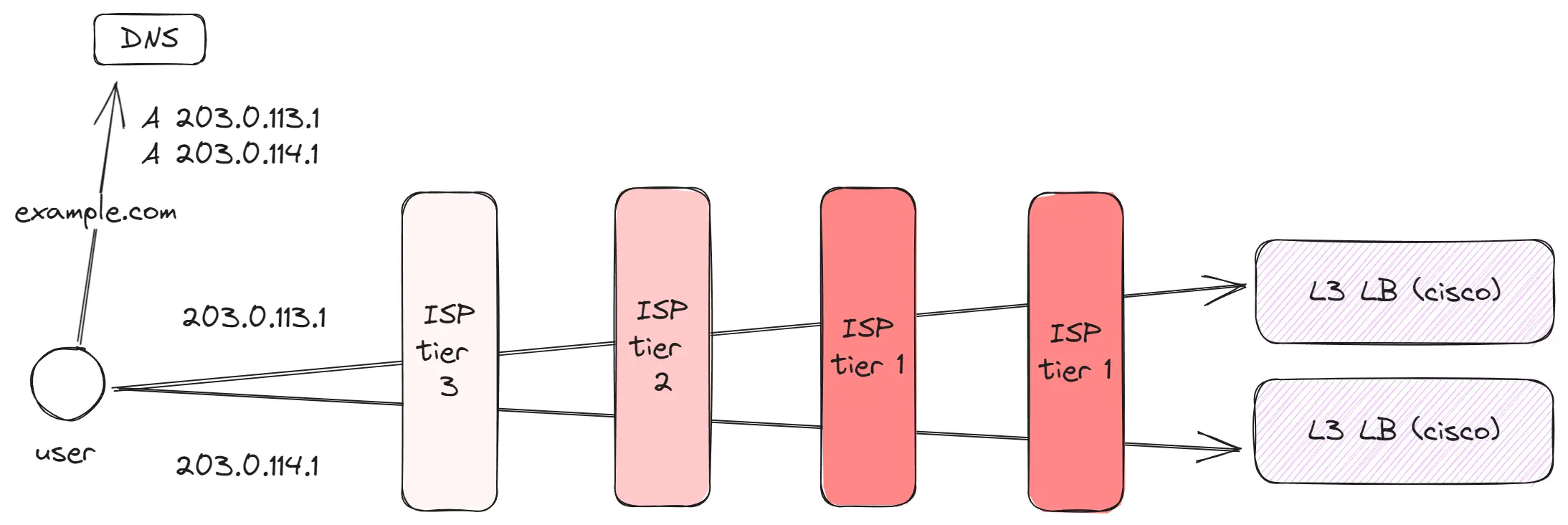
Это несколько десятков глобальных игроков, контролирующих основные коммуникационные каналы между различными географическими точками — например, между Европой и Америкой или Америкой и Азией. Благодаря им, находясь, например, в Европе, можно без проблем посетить сайт, размещенный в Японии.
Основные моменты:
- Tier 1 провайдеры обладают огромными каналами, соединяющими различные части мира. Например, существуют каналы, связывающие Европу с Америкой или Америку с Азией.
- Между отдаленными регионами, такими как Европа и Азия, функционирует несколько различных каналов.
- Некоторые запросы могут быть проходить через несколько Tier 1 провайдеров.
Как пользователь находит сервер по IP адресу? (BGP, Anycast)
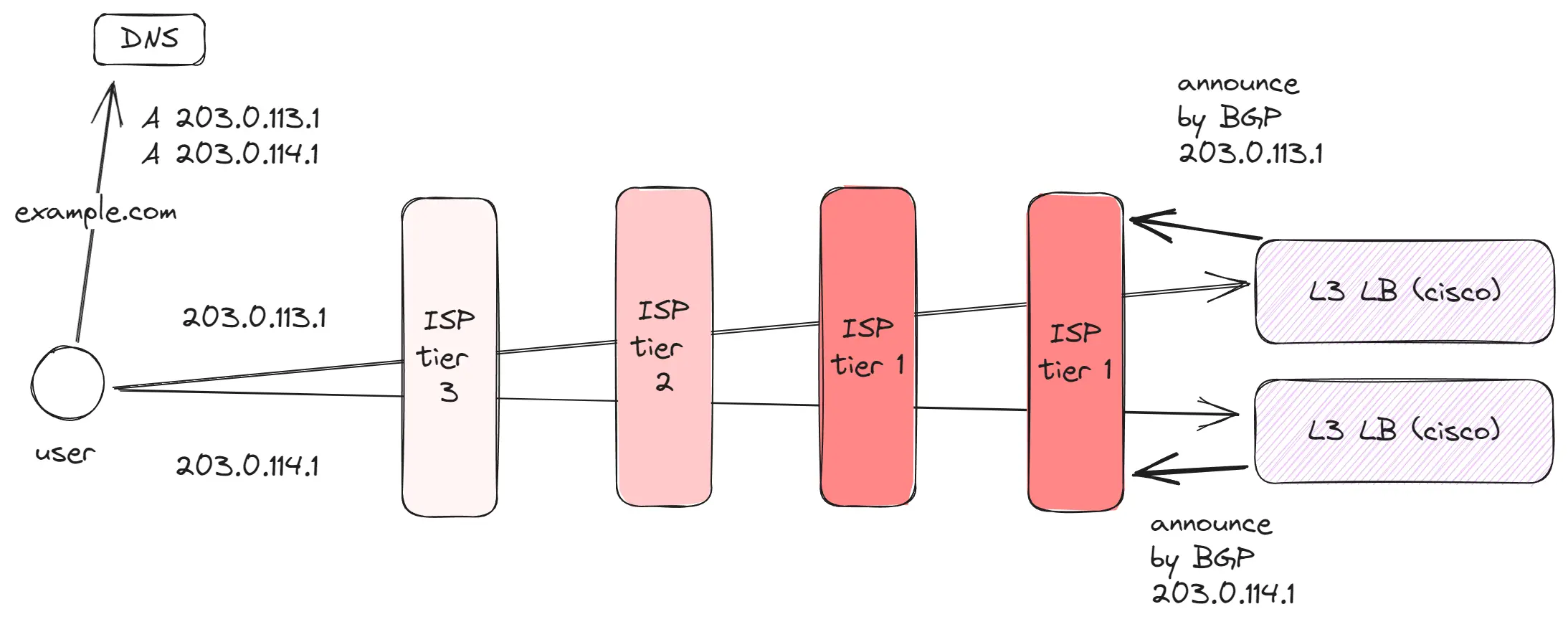
Существует миллионы IP-адресов. Как же обычный клиент, подключенный к интернету, может определить, куда направлять запросы по IP-адресу?
- Сервер использует
BGPдля анонсирования своего IP-адреса ближайшему провайдеру уровняTier 1илиTier 2.BGP— это протокол, который принимается и используется всеми интернет-провайдерами. В нем хранится информация о серверах, способных принимать трафик по определенным IP-адресам. - После того как наш сервер сообщил информацию о своем IP-адресе до провайдера уровня
Tier 1, этот провайдер передает эту информацию всем соседним провайдерам уровнейTier 1иTier 2, которые, в свою очередь, делятся ей с уровнемTier 3. - Когда пользователь делает запрос по IP-адресу, он передает запрос к уровню
Tier 3. Получив запрос,Tier 3проверяет таблицу маршрутизации, чтобы определить, какой следующий сервер анонсировал данный IP-адрес, и перенаправляет туда пакет. Этот процесс продолжается до тех пор, пока запрос не достигнет целевого сервера.
Этот механизм предоставляют возможность для дополнительных оптимизаций:
- Anycast позволяет использовать один и тот же IP-адрес в разных точках мира, что уменьшает задержку и повышает доступность. Таким образом, на уровне
Tier 2можно установить сервер, который будет анонсировать этот же IP-адрес. В результате в интернете появится два сервера, способных обрабатывать трафик с одного IP-адреса. При этом ближайшие клиенты будут подключаться к наиболее близкому серверу, и трафик будет направляться к нему.
Edge networks
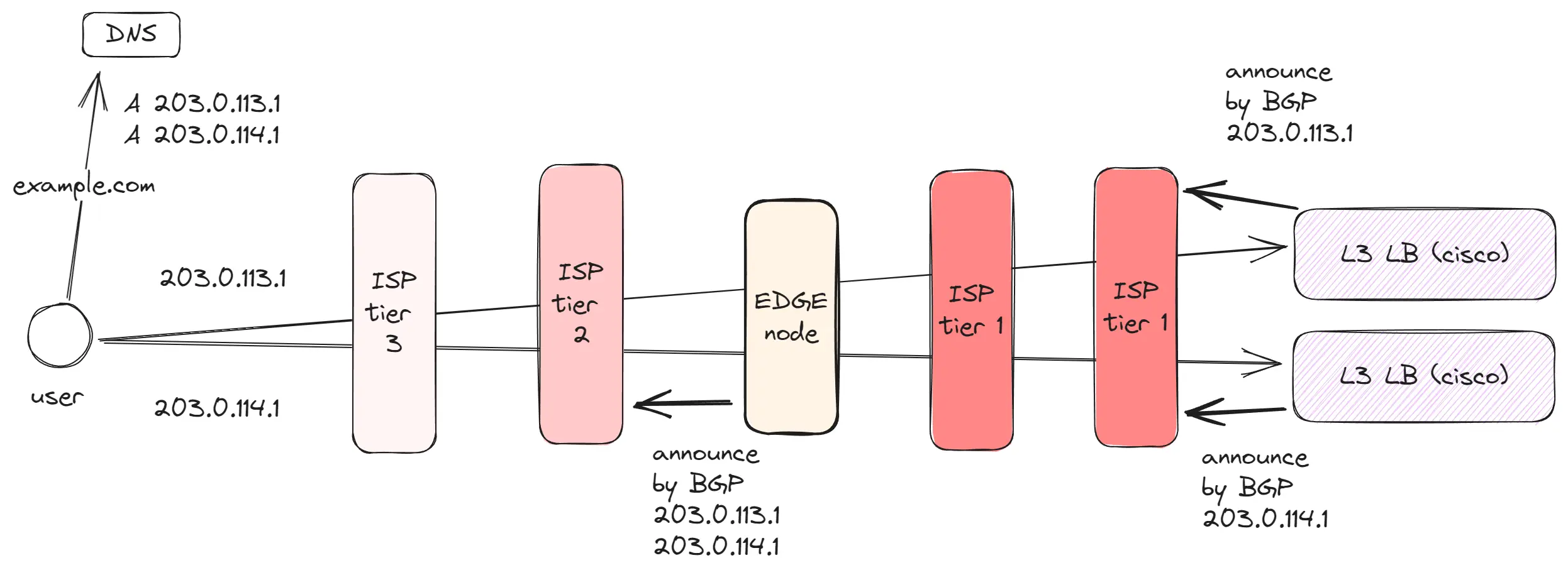
BGP и Anycast создают условия для разработки Edge networks, которые активно используют такие компании, как AWS, Cloudflare и Google. Количество дата-центров ограничено и сотни миллионов пользователей находятся на расстоянии от этих дата-центров. Однако, нам необходимо, чтобы эти пользователи могли быстро загружать данные и иметь быстрое соединение.
В качестве решения в различных географических точках арендуется место в дата-центрах, где размещается оборудование компаний. На примере Google: у них 39 дата-центров и 187 точек, в которых установлено Edge оборудование. Edge network содержит:
- Проксирующее оборудование, которое анонсирует IP-адреса с использованием Anycast. Анонсируя IP-адрес в разных точках, пользователи подключаются к ближайшему серверу, что уменьшает задержку. Так как Между пользователем и оборудованием Edge меньше расстояния, то меньше ping как результат TCP соединения устанавливаются быстрее. А также между Edge и дата-центром, устанавливаются качественные/выделенные соединения для передачи данных.
- Кэширующее оборудование, которое сохраняет часто запрашиваемые данные в регионе, такие как изображения, видео, JS-файлы и другие активы. Это позволяет снизить нагрузку на канал до дата-центра и ускорить загрузку данных для пользователей.
- Edge Computing, некоторые компании, такие как CloudFlare пошли дальше и позволяют запускать код на Edge оборудовании. Это позволяет создавать backend-приложения которые находятся очень близко к пользователям. Таким образом, даже удаленные пользователи получают данные так же быстро, как и те, кто находится рядом с дата-центром.
Data Center Networks
Теперь самое интересное. На самом деле дата-центры выглядят иначе, чем я показывал ранее. Предыдущие схемы скорее отражали, какой путь проходит пакет в упрощенном виде, который удобно использовать, когда я пишу дизайн-документы. Однако в реальности дата-центры настроены на обработку огромного количества разного трафика с низкой задержкой. Я буду разбирать на примере дата-центров, которые использует компания Meta, рассказывающей подробно о своих ДЦ. За что им большое спасибо. Стоит добавить, что у Meta передовые дата-центры, и увы, не у всех такие же.
Какие особенности у новых дата-центров:
- Модульный дизайн: дата-центры строятся и проектируются как блоки, которые можно легко добавлять или убирать. Каждый блок содержит все необходимое оборудование с продуманной архитектурой сети. Это упрощает архитектуру и унифицирует оборудование.
- Требования к энергии, пропускной способности и площади. Дата-центры — это физические объекты, и поэтому возникают дополнительные особенности. Нельзя просто добавить множество серверов, если нет нужной энергии, канала связи и площади.
- Огромные скорости: дата-центры оперируют сотнями терабитов данных в секунду. Например, мой домашний интернет — это всего 0.5 гигабита в секунду, что в тысячи раз меньше.
- Дата-центры включены в регионы: на практике компании не строят просто один ДЦ, а формируют регион, включающий 3 или более ДЦ, которые еще называют зонами. Эти зоны расположены рядом друг с другом, имеют разные источники энергии и каналы связи, и соединены между собой выделенными линиями связи. Таким образом, если один ДЦ выходит из строя, другие могут взять на себя его нагрузку, и пользователи не заметят проблемы при условии, что сервис был правильно спроектирован.
- Ориентированы на внутренний трафик: в нашем мире 80% и более трафика в дата-центре — это внутренний трафик, который не выходит наружу. Это связано с тем, что при поступлении запроса пользователя к сервису, нам часто нужно обратиться к кэшу, базе данных, другим сервисам, аналитике. Важна минимальная задержка для внутренних запросов.
Перейдем к разбору того, как устроена зона Zone.
Rack
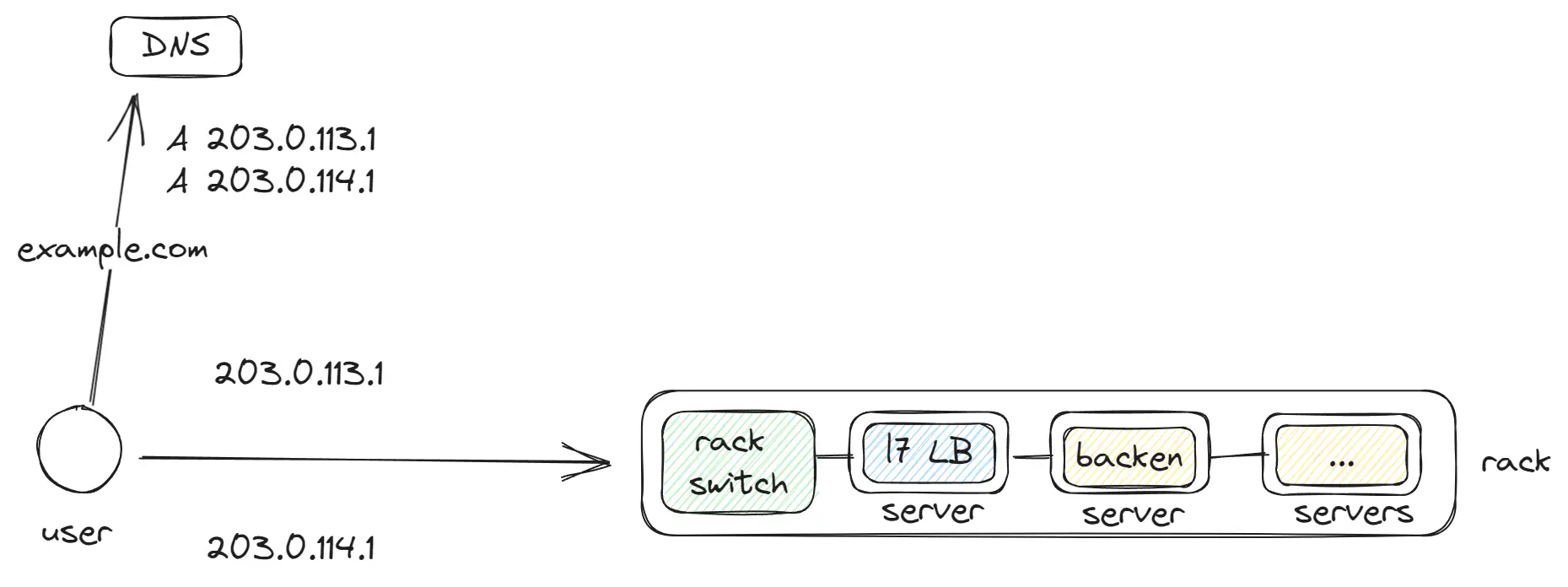
Rack это минимальная единица в дата-центре, к которой подключены множество серверов. Внутри этих серверов запускаются контейнеры (типа Docker), а внутри них — приложения, L7 LB, базы данных. Каждый Rack оснащен rack switch, к которому подключены остальные серверы и который обрабатывает весь трафик.
В одном дата-центре или регионе может быть тысячи таких Rack.
Fabric switch
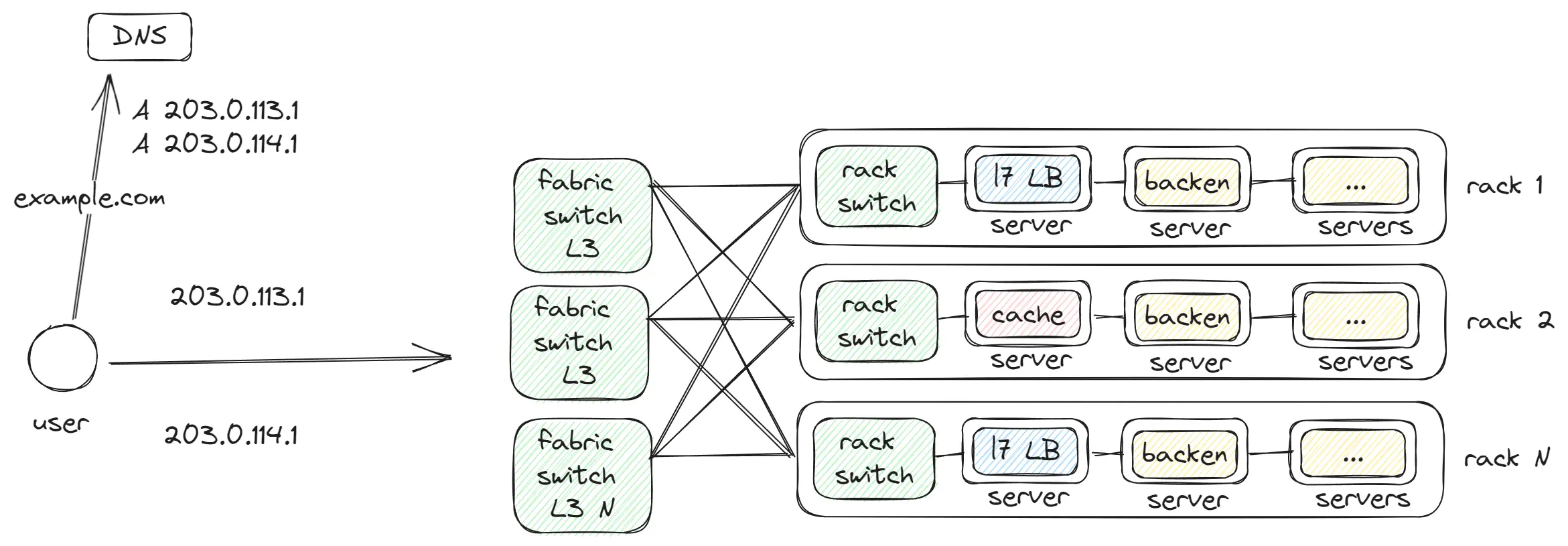
Fabric switch — это сетевое оборудование, которое соединяет группы rack switch. Наши приложения активно обмениваются данными между собой, и все эти сервисы часто расположены на соседних Rack. Для достижения минимальной задержки используется оборудование, соединяющее до 128 Rack в одну сеть. Таким образом, запрос из Rack 1 может попасть в Rack 2 за один hop.
Но fabric switch может подключить до 128 rack switch, и поэтому нам нужны дополнительные уровни для соединения fabric switch между собой.
Spine switch
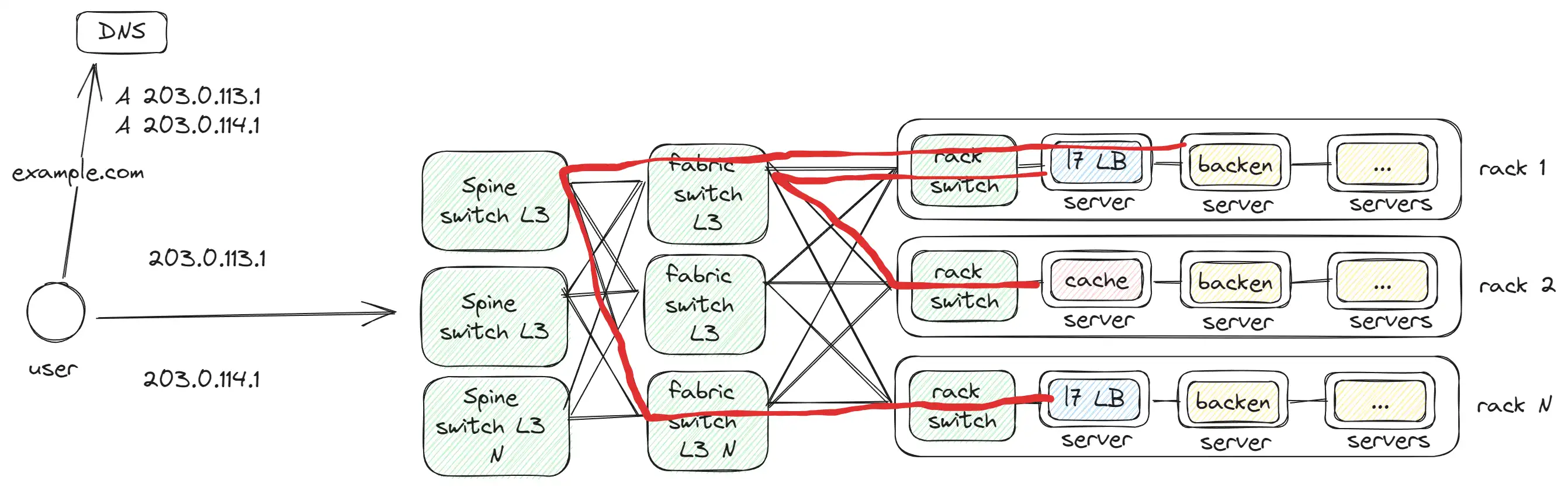
Spine switch соединяет между собой fabric switch, так как мы сталкиваемся с ограничением на количество доступных портов на Fabric switch. Примерно схожая проблема, которая у нас была ранее с L7/L4/L3
Красная линия, это пример как происходит общение:
- между 2
Rackза 1 hop, так как они подключены к одномуFabric switch. - между 2
Rackза 3 hops, так как они подключены к разнымSpine switch.
Fabric aggregator и Zone
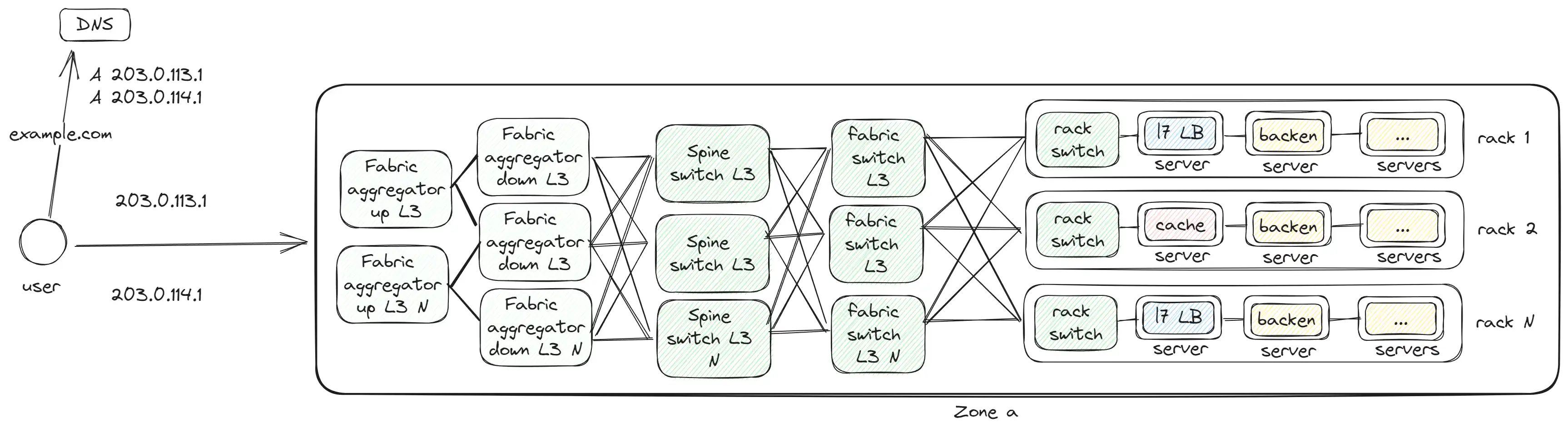
С добавлением Fabric aggregator формируется полноценная зона или дата-центр. Это уже уровень полноценного большого здания
Fabric aggregator соединяет разные зоны между собой, и через него проходит внешний трафик. Учитывая большой объем внутреннего трафика, требуется разное оборудование для внешнего и внутреннего трафика. Поэтому Meta разделила его на два уровня:
- Fabric aggregator down — обрабатывает внутренний трафик между разными зонами и соединен с каждым Spine switch других зон.
- Fabric aggregator up — обрабатывает внешний трафик, исходящий или входящий извне.
Region
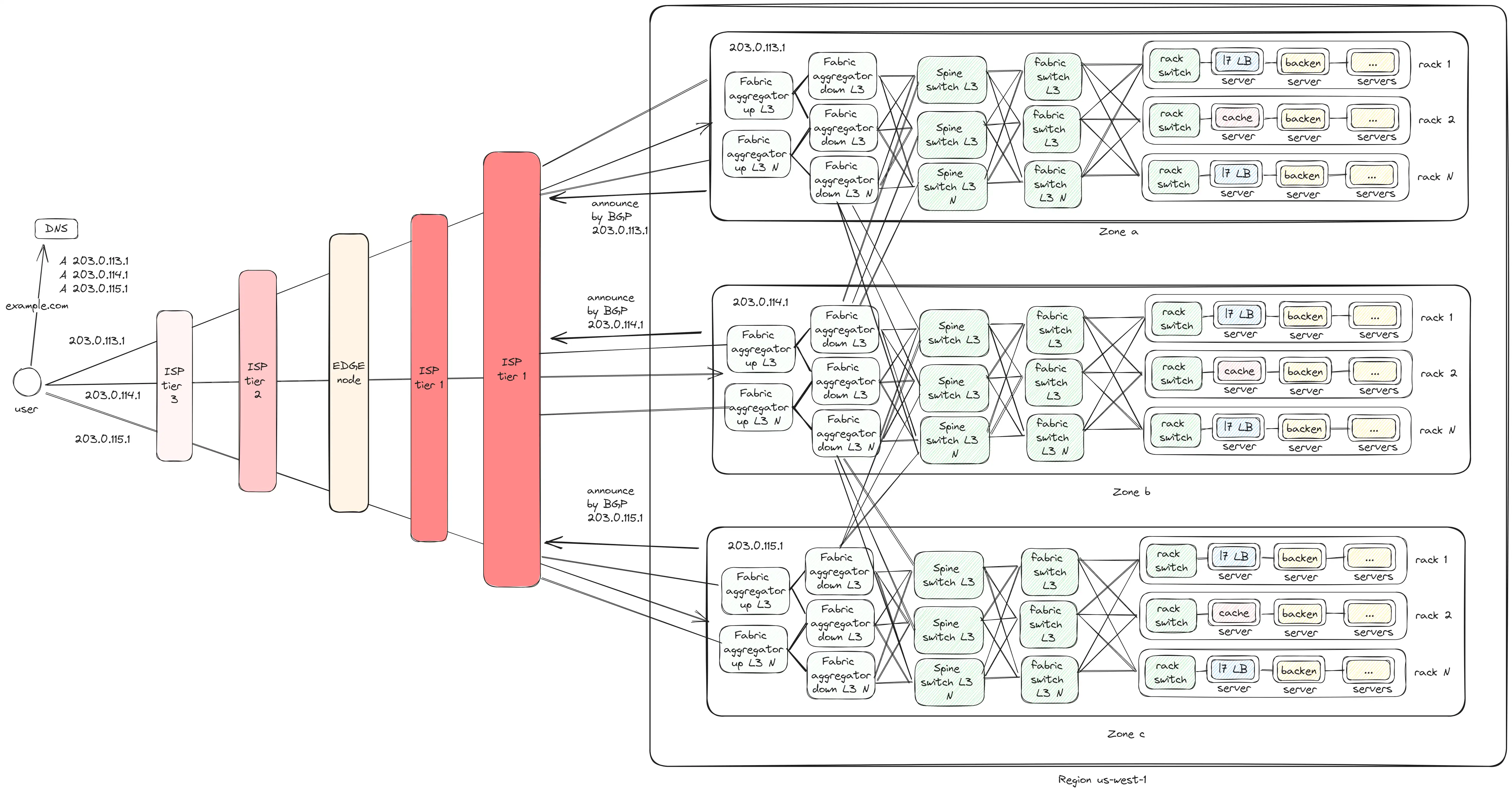
В итоге мы приходим к финальному варианту, где у нас есть 3 региона:
- Все регионы соединены между собой через
Fabric aggregator down. - Регионы подключены к
ISPчерезFabric aggregator up. - Регионы анонсируют себя через
BGP, чтобы пользователи могли найти их по IP-адресу. - Запросы внутри одного Zone выполняются с максимум 6 hops, между Zone — 8 hops.
Дополнительные моменты
Дальнейшее масштабирование
Всё это можно масштабировать, и в результате получить 6 зон в одном регионе, что будет выглядеть действительно эпично.
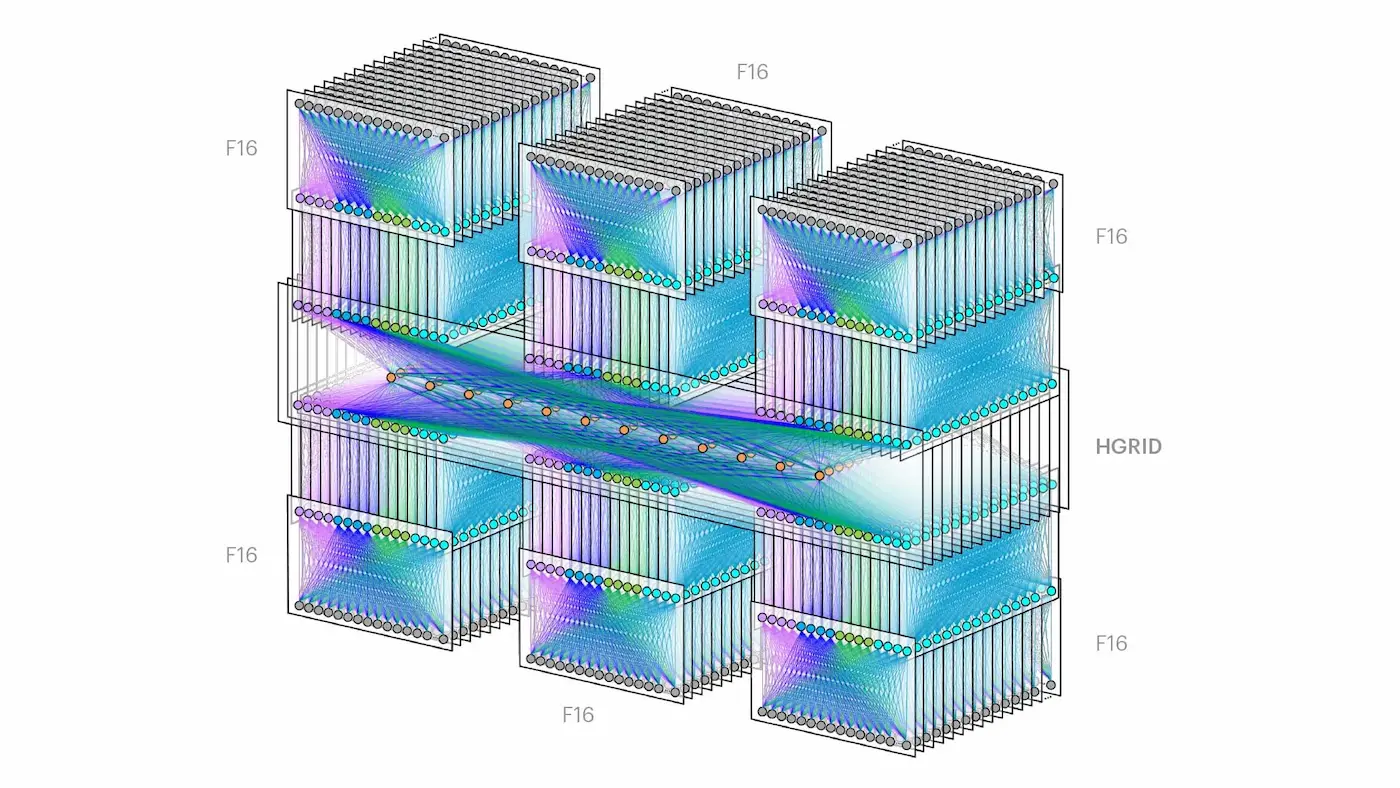 И не понятным на первый взгляд. Однако, если разобраться, то каждая “башня” — это
И не понятным на первый взгляд. Однако, если разобраться, то каждая “башня” — это Zone из моей схемы, а посередине расположен слой Fabric aggregator. Однако у меня всё равно возникают вопросы: сколько проводов понадобится, чтобы всё это соединить?
Рекомендации по разработке приложений
Рекомендую планировать архитектуру и инфраструктуру проекта с учётом использования локального трафика внутри Zone, синхронизируя данные только между зонами и регионами. Таким образом, можно добиться минимальной задержки и стоимости, так как трафик между зонами и, особенно, между регионами является платным.
Почему делают 3+ Zones в Region, а не 2 или 1?
Всё дело в резервировании. Дата-центры, инфраструктура и системы должны проектироваться с учетом того, что часть системы может выйти из строя. Множество причин могут стать причиной такого сбоя: прерывание интернет-канала, отсутствие электроэнергии или пожар. С учётом этого риска нам необходима резервная система, которая сможет перехватить нагрузку. Рассмотрим пример, когда нам требуется обработать 10 000 rps:
- Если у нас 2 ДЦ/Region в одном регионе, каждому из них потребуется ресурсы на обработку 10 000 RPS. Если выйдет из строя 1 ДЦ, у другого будет ресурсы на обработку. Это означает, что дополнительные 10 000 rps будут простаивать в резерве.
- При 3 ДЦ в одном регионе каждому достаточно ресурсов для обработки 5 000 RPS, что снижает резерв до 5 000 rps.
Таким образом, иметь минимум 3 ДЦ/Region в одном регионе гораздо экономичнее с точки зрения ресурсов.
Выводы
Сетевое взаимодействие — это огромная и интересная тема. Я покрыл только часть вопросов, не углубляясь в такие вопросы как виртуальные сети, разделение сети на внешнюю и внутреннюю и многие другие. Благодарю за уделённое время. Если вы нашли неточности, ошибки или у вас есть что добавить, пожалуйста, напишите в комментариях. Я буду рад обсудить.
Sources
- https://research.google/pubs/pub44824/
- https://cloud.google.com/load-balancing/docs/application-load-balancer
- https://www.nextplatform.com/2021/11/11/getting-meta-abstracting-and-multisourcing-the-network-like-an-fboss/
- https://www.youtube.com/watch?v=rRxGJbu8nqs
- https://engineering.fb.com/2019/03/14/data-center-engineering/f16-minipack/
- https://cloud.google.com/about/locations#lightbox-regions-map
- https://cloud.google.com/compute/docs/ip-addresses#reservedaddress